任务二:数据采集
数据采集将直接影响数据清洗、分析、可视化。本任务提供四个脱敏数据源:交通运输、招聘、酒店、零售。
请使用企业生产环境常用采集工具和网络爬虫相关技术,完成网页分析、数据采集、数据爬取,数据存储,并将采集数据进一步进行相关数据操作。
一、 数据源 1(交通运输)
航空出行由于它的快捷便利,已经被越来越多的人喜欢,某航空公司通过多年运营,积累了大量会员档案和乘坐航班信息,为对客户进行分群,明确价值客户群体,将有限的营销资源集中于高价值客户,实现企业利润最大化。为此,该航空公司聘请“H3CU”大数据分析公司完成此项目。
由于会员信息属于公司机密数据,该航空公司将数据脱敏后以 csv 文件传送给“H3CU”公司进行数据处理与分析,为安全考虑“H3CU”公司需将数据先存入数据库中备份,再进一步数据清洗与分析。请参考一下相关专业说明完成任务。
1、航空公司积累了大量会员档案信息和乘坐航班信息,其中包含了会员卡号、GZ-2019032 大数据技术与应用(高职组)赛题库
入会时间、性别、年龄、会员卡级别、在观测窗口内的飞行公里数、飞行时间、飞行次数等 44 个特征属性,数据存放在 csv 格式文件中。
2、识别客户价值应用最广泛的模型是 RFM 模型。其中,R(Recency)指的是最近一次消费时间与截止时间的时间间隔,通常R值越小,客户对商品或服务最可能感兴趣。F(Frequency)指顾客某段时间的消费次数,次数越高,顾客价值越大。M(Monetary)指顾客在某段时间内的消费金额。
3、由于在本任务中,同样消费金额的不同客户,对航空公司的价值是不同,比如,一位购买长航线、低等级舱位的旅客与一位购买短航线、高等级舱位的旅客相比,可能票价是一样,但后者对航空公司的价值可能更高。所以,用累计行程M和乘坐舱位对应的折扣系数 C 代替消费金额。
4、航空公司会员入会时间也一定程度影响客户价值,因此增加客户关系长度 L做为另一特征。构建出包含 6 个特征的模型,分别和原始数据中的 FFP_DATE(入会时间)、LOAD_TIME(观测窗口结束时间)、FLIGHT_COUNT(观测窗口内的飞行次数)、AVG_DISCOUNT(平均折扣系数)、SEG_KM_SUM(观测窗口的总飞行千米数)、LAST_TO_END(最后一次乘机时间至观测窗口结束时长)。
本次任务包括以下内容:
1、使用 Java 或 Python 语言编写程序,将给定csv格式的数据文件写入Mysql数据库中,并将代码与运行结果截图保存。
1)导入模块
2)连接数据库
3)创建表,表名称
4)将数据写入数据库
5)关闭数据库
2、使用数据传输工具,将Mysql数据库中的航空数据导入大数据平台中进行数据清洗,并将命令与运行结果截图并保存。
二、 数据源 2(web,招聘)
1、网站解析,利用 chrome 查看网页源码,分析招聘网站网页结构。
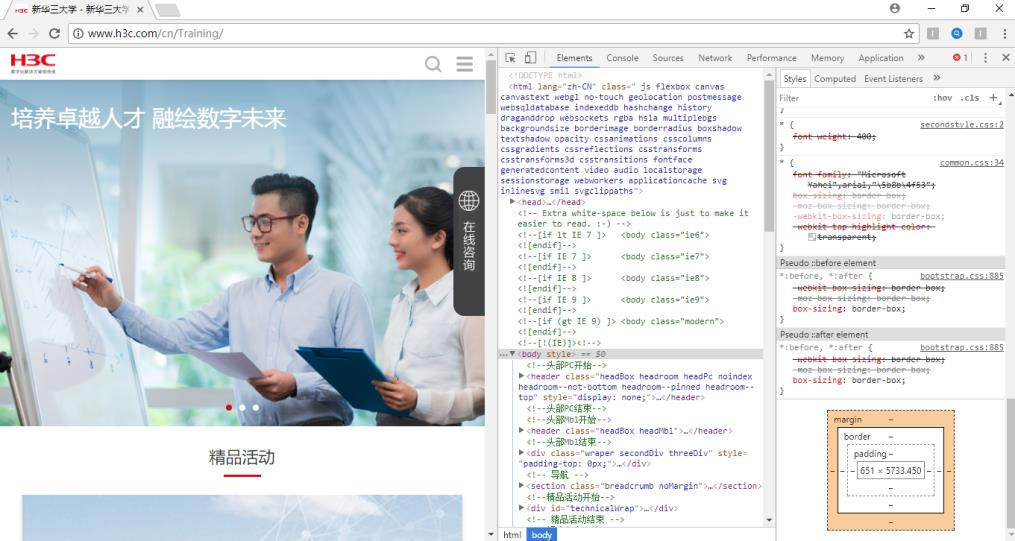
1)“检查”招聘网站,在网页中右键点击检查,或者 F12 快捷键,进入如下图的查看元素页面。
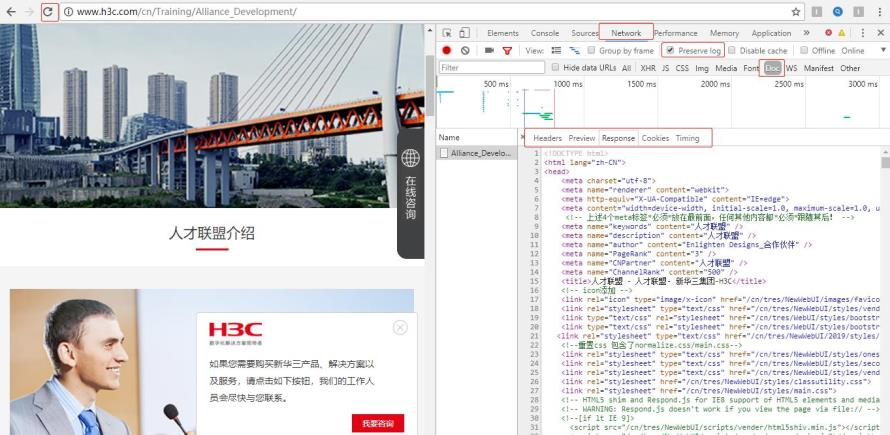
2)检查网站:点击 Network、勾选 Preserve log、点击 Doc、点击清理按钮、刷新页面、点击 Response,在 Response 查看所需内容。
2、从招聘网站中爬取需要数据,按照要求使用 Java 或 Python 语言编写并完 善爬虫代码,爬取指定数据项,有效数据项包括但不限于:所在城市、公司名称、薪资、技能要求等多项字段。并将代码文件与代码截图保存。
具体步骤如下:
1)创建爬虫项目\H3CU_recruit\
2)构建爬虫请求
3)按要求定义相关字段
4)获取有效数据
5)将爬取到的数据保存到指定位置
3、至此已从招聘网站中爬取了所需数据,下一步我们要将爬取结果进一步进行相关数据操作,请将操作命令截图并保存。
三、 数据源 3(web,酒店)
1、 网站源码解析:利用 chrome 查看网页源码,分析酒店网站网页结构。
1)“检查”酒店网站,在网页中右键点击检查,或者 F12 快捷键,进入如下图的查看元素页面;
2)检查网站:点击 Network、勾选 Preserve log、点击 Doc、点击清理按钮、刷新页面、查看所需内容。
2、 从酒店网站中爬取需要数据,按照要求使用 Java 或 Python 语言编写并完善爬虫代码,爬取指定数据项,有效数据项包括但不限于:城市、商圈、星级、评分、评论数等多项字段。并将代码文件与代码截图保存
具体步骤如下:
1)创建爬虫项目\H3CU_hotel\
2)构建爬虫请求
3)按要求定义相关字段
4)获取有效数据
5)将爬取到的数据保存到指定位置
至此已从酒店网站中爬取了所需数据,下一步我们要将爬取结果进一步进行相关数据操作,请将操作命令截图并保存。
四、 数据源 4(web,零售)
1、网站解析,利用 chrome 查看网页源码,分析零售网站网页结构。
1)“检查”零售网站,在网页中右键点击检查,或者 F12 快捷键,进入如下图的查看元素页面;
2)检查网站:点击 Network、勾选 Preserve log、点击 Doc、点击清理按钮、刷新页面、点击 Response,在 Response 查看所需内容。
2、从零售网站中爬取需要数据,按照要求使用 Java 或 Python 语言编写并完善爬虫代码,爬取指定数据项,有效数据项包括但不限于:客户信息、员工信息、商品信息、商场信息等多项字段。并将代码文件与代码截图保存。
具体步骤如下:
1)创建爬虫项目\H3CU_mart\
2)构建爬虫请求
3)按要求定义相关字段
4)获取有效数据
5)将爬取到的数据保存到指定位置
3、至此已从零售网站中爬取了所需数据,下一步我们要将爬取结果进一步进行相关数据操作,请将操作命令截图并保存。
